
| Übungsaufgabe Scanner |
Was ist ein Scanner?Die erste Teilaufgabe eines Compilers umfasst die lexikalische Analyse des Eingabetextes. Betrachtet man Beispielsweise folgenden C Quelltext für ein Hallo Welt Programm:
int main(void)
{
printf("Hallo Welt!\n"); // Textausgabe
return 0; // Programmende
}
Aber auch der nachfolgende Quelltext steht für das gleiche Programm:
int main( void ) { printf ( "Hallo Welt!\n" ) ; return 0; }
Der offensichtliche Unterschied besteht in der Verwendung von Tabs, Leerzeichen, Zeilenumbrüchen und Kommentaren um den Quelltext für den Leser aufzubereiten. Diese sind jedoch von der Programmiersprache C nicht gefordert und das entstehende Programm ist nach dem Übersetzen beider Quellcodes identisch.Der Scanner hat die Aufgabe, Schlüsselworte im Eingabetext zu erkennen und zu klassifizieren, aber auch unwichtige Zeichen (wie zusätzliches Leerzeichen) zu "überlesen". Diesen Vorgang der Zuordnung, von Eingabetextfragmenten zu Klassen (engl. Token), nennt man auch "Tokenizing". Arbeitsweise eines ScannersMeist werden die einzelnen Token mit Hilfe von regulären Ausdrücken definiert. Technisch werden diese Ausdrücke wiederum durch zusammengesetzte endliche Automaten realisiert.Beispiel für ein Token "Zahl": Zahl: [0-9]+Der äquivalente endliche Automat für diesen Ausdruck: 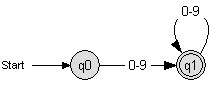 Da sich mehrere Token in ihren regulären Ausdrücken überlappen können, verwendet ein Scanner Regeln welches Token für ein bestimmtes Eingabetextfragment gewählt wird. Beispiel:
Zahl: [0-9]+
Telefon: \+49/[0-9]{2,4}/[0-9]{3,}
Eine Telefonnummer beinhaltet mehrmals das Token Zahl, ist aber deutlich spezifischer als das allgemeine Token Zahl. Bei derartigen Mehrdeutigkeiten entscheidet der Scanner zugunsten des längsten erkannten Token (nicht der längsten/komplexesten reguläre Ausdruck, sondern das mit diesem Ausdruck längste beschriebene Eingabetextfragment). Sollten mehrere Token mit gleicher Länge gefunden werden, entscheidet der Scanner in der Regel für das Token, welches in der Token-Definitionsliste am weitesten oben steht.Diese Regeln muss der Entwickler bei der Aufstellung der Token entsprechend beachten. AufgabeEntwickeln Sie die Token mit den entsprechenden regulären Ausdrücken für die lexikalische Analyse einer einfachen selbst gewählten Grammatik (z.B.: für arithmetische Ausdrücke).Geben Sie die Token / Pattern Paare in VCC ein und erstellen Sie eine leere Regel auf der Parser-Seite (verwenden Sie C# als Sprache). Erstellen Sie mit "Compiler generieren" den Compiler. Testen Sie mit verschiedenen Eingabetexten und dem Parameter -t ob die Token entsprechend erkannt werden (compiler.exe -t eingabe.txt). Verwenden Sie abschließend das Spezial-Token "Ignore" um Leerzeichen zu ignorieren. |